
Security Mindset in the Manhattan Project
We've spent too long at the End of History

Here’s a story about the last 75 or so years: Our last great technology was nuclear. It almost ended the world a number of times. For some reason, scientific and technological progress stagnated. Now we’re on the cusp of a new great technology, AI, and we’re about to emerge from that stagnation. We’re entering back into a precarious world.
Maybe that’s fine — but our mindset isn’t prepared for it.
I started thinking about this last week when we saw a tweet from Mike Solana.
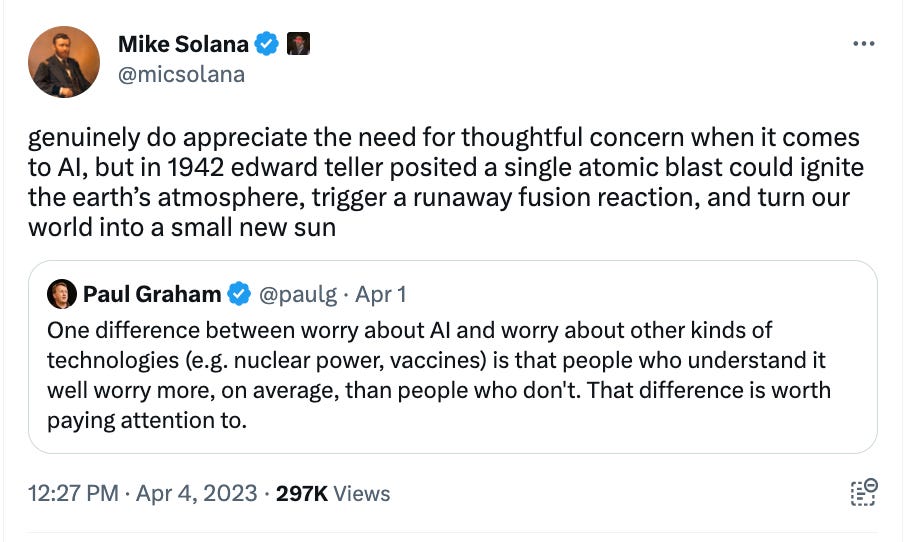
I think Solana has a reasonable point here: You must sometimes act in the face of risk and uncertainty. But I also don’t think it does justice to the degree of security and caution exercised during the Manhattan Project.
Consider Hans Bethe's account:
Bethe: It is such absolute nonsense [laughter], and the public has been interested in it… And possibly it would be good to kill it once more. So one day at Berkeley -- we were a very small group, maybe eight physicists or so -- one day Teller came to the office and said, "Well, what would happen to the air if an atomic bomb were exploded in the air?" The original idea about the hydrogen bomb was that one would explode an atomic bomb and then simply the heat from the atomic bomb would ignite a large vessel of deuterium… and make it react. So Teller said, "Well, how about the air? There's nitrogen in the air, and you can have a nuclear reaction in which two nitrogen nuclei collide and become oxygen plus carbon, and in this process you set free a lot of energy. Couldn't that happen?" And that caused great excitement.
Horgan: This is in ‘42?
Bethe: '42. Oppenheimer [soon to be appointed head of Los Alamos Laboratory] got quite excited and said, "That's a terrible possibility," and he went to his superior, who was Arthur Compton, the director of the Chicago Laboratory, and told him that. Well, I sat down and looked at the problem, about whether two nitrogen nuclei could penetrate each other and make that nuclear reaction, and I found that it was just incredibly unlikely. And I said so, and I think Teller was very quickly convinced and so was Oppenheimer when he'd returned from seeing Compton. Later on we found out that it is very difficult to ignite deuterium by an atomic bomb, and liquid deuterium, which is much easier to ignite than the gas, but at the time in '42 we thought it might be very easy to ignite liquid deuterium. Well, Teller, I think he has to be much commended for that. Teller at Los Alamos put a very good calculator on this problem, [Emil] Konopinski, who was an expert on weak interactors, and Konopinski together with [inaudible] showed that it was incredibly impossible to set the hydrogen, to set the atmosphere on fire. They wrote one or two very good papers on it, and that put the question really at rest. They showed in great detail why it is impossible. But, of course, it spooked [Compton]. Well, let me first say one other thing: Fermi, of course, didn't believe that this was possible, but just to relieve the tension at the Los Alamos [Trinity] test [on July 16, 1945], he said, "Now, let's make a bet whether the atmosphere will be set on fire by this test." [laughter] And I think maybe a few people took that bet. But, for instance, in Compton's mind it was not set to rest. He didn't see my calculations. He even less saw Konopinski’s much better calculations, so it was still spooking in his mind when he gave an interview at some point, and so it got into the open literature, and people are still excited about it.
Horgan: When did Compton give his interview?
Bethe: After the War. I don’t know precisely when. Maybe, I don't know, '47, '48. Some such time. [The date was 1959. See Addendum.] And that got other people excited, and there was one exchange of letters in the Bulletin of the Atomic Scientists, but by then of course it was absolutely clear, and it was absolutely clear before the Los Alamos test that nothing like that would happen. In this form, I think I have no objection to your writing it.
Horgan: I think what makes it such a fascinating episode… is the idea of doing a calculation on which possibly could rest the fate of the world. [laughter]
Bethe: Right, right.
Horgan: That's obviously an extraordinary kind of calculation to do. Did you have any... Did you even think about that issue when you saw the Trinity test?
Bethe: No.
Horgan: You were absolutely--
Bethe: Yes.
Horgan: — completely certain.
This is not an attitude of, “Things just work themselves out.” Some of the best minds of their generation — Bethe, Teller, Oppenheimer — actually did calculations to prove that the atmosphere igniting wasn’t possible and reviewed those calculations together. “Irresponsible” somehow fails to describe how negligent it would have been not to check.
Toby Ord and others have criticized this incident,1 suggesting Trinity was still reckless given the possibility an error in the calculations. Arthur Compton, already a Nobel laureate, for some reason had still not been persuaded.
Ord might be right — in the sense we should never bet the fate of the world — but I see the situation as primarily suggesting quite an admirable account of security and care during not just a technological race, but a wartime one.
There’s a helpful term here: Security Mindset. It was coined by Schneier on Security, a blog on computer security:
Security professionals — at least the good ones — see the world differently. They can’t walk into a store without noticing how they might shoplift. They can’t use a computer without wondering about the security vulnerabilities.
It’s the only way to ensure software is safe. And yet:
It’s not natural for engineers. Good engineering involves thinking about how things can be made to work; the security mindset involves thinking about how things can be made to fail.
I think coming out of the great stagnation — where for almost 50 years we've neither had technology radically reshaping the physical world nor lived under the imminent threat of a geopolitical rival — we’ve lost our security mindset.2
We don’t even really remember things can be dangerous.
Obviously bad ideas, like “open sourcing AI,”3 get play from otherwise reasonable people. We're so eager to start building some good technology in the world of atoms that security mindset concerns sounds like a NEPA form (See also: cheems4). But in a precarious world, the only reasonable approach is the one informed by security mindset.
This is how I think about AI safety, in the broadest sense: In a wide range of AI scenarios, we will need to exercise much more security mindset in our operation and decision making.5
If AI is — as Leopold Aschenbrenner suggests — the greatest weapon mankind will ever create, even doing as well as the Manhattan project is not enough. The Soviet Union had at least three successful spies in Los Alamos and they successfully dropped a bomb four years later.
We need to be much, much better.
We’re certainly not on the ball for alignment, but our current norms around security might be even worse. It’s not just security, in the narrow sense of system vulnerabilities, either. The Manhattan Project was made possible by 12 years of cooperation between scientists, technologists, politicians, and military leaders. It’s that collaboration, coordination, and spirit that make security possible at scale.6
Security mindset isn’t the most difficult model to see the world in. Per Schneier: Anyone can exercise his security mindset simply by trying to look at the world from an attacker’s perspective. But we need to start employing it.
We Are as Gods and Might as Well Get Good at It

Ord seems to believe the ex ante probability of igniting the atmosphere was a bit higher than I do, though he might be being rhetorical. There’s some inconsistency in the accounts of different scientists but that’s mostly beside the point.
We did, obviously, exercise security mindset in some areas: Computer security and gain-of-function labs come to mind. Though come to think of it, those examples may make the point.
I’m talking about posting model weights, not allowing access to the Open AI API. More extensive treatment another time, but in short the benefits to open source usually seem relatively limited and in this case it might massively accelerate Chinese AI progress.
You might only get to be anti-cheems by selling your level of risk taking to society at large.
In fact, I think it extends beyond AI. In almost any post-great stagnation world, existential risk will be higher, at least for a time. Security Mindset is most important during the time of perils.
This relates to my frustration with contrarianism: We need to be getting serious! More on this soon.
I agree with your arguments, but I would argue that the focus should be broader. AI requires careful consideration, which likely won't happen.
I'm also concerned about the false sense of security entertained by the West since the end of WWII...the idea that we were done with hot (and cold) wars.
Even with a proxy war in Ukraine, and cold wars with China and Iran (and whatever it is that's happening with Mexico), there's no discernible change in attitudes or behaviors throughout most of the West, but especially in the US.
Ditto climate change, democratic rule, etc.
Will AI fix any existing problems or just distract attention (and money) from solutions?
We seem like children who play with a toy until it breaks or we're bored, then move to the next one.
Good piece, Nick. I particularly appreciate you pasting in Hans Bethe's account of what happened – I hadn't come across it before. Illuminating, changes my priors on AI risk slightly. Thanks...